Euclidean neural networks
What is e3nn?
e3nn is a python library based on pytorch to create equivariant neural networks for the group \(O(3)\).
Where to start?
Guide to the
e3nn.o3.Irreps: Irreducible representationsGuide to implement a Convolution
The simplest example to start with is Tetris Polynomial Example.
Guide to implement a Transformer
Demonstration
All the functions to manipulate rotations (rotation matrices, Euler angles, quaternions, convertions, …) can be found here Parametrization of Rotations.
The irreducible representations of \(O(3)\) (more info at Irreps) are represented by the class e3nn.o3.Irrep.
The direct sum of multiple irrep is described by an object e3nn.o3.Irreps.
If two tensors \(x\) and \(y\) transforms as \(D_x = 2 \times 1_o\) (two vectors) and \(D_y = 0_e + 1_e\) (a scalar and a pseudovector) respectively, where the indices \(e\) and \(o\) stand for even and odd – the representation of parity,
import torch
from e3nn import o3
irreps_x = o3.Irreps('2x1o')
irreps_y = o3.Irreps('0e + 1e')
x = irreps_x.randn(-1)
y = irreps_y.randn(-1)
irreps_x.dim, irreps_y.dim
(6, 4)
their outer product is a \(6 \times 4\) matrix of two indices \(A_{ij} = x_i y_j\).
A = torch.einsum('i,j', x, y)
A
tensor([[-0.6943, -0.7062, -0.2921, 0.5574],
[-0.1569, -0.1596, -0.0660, 0.1260],
[-0.8311, -0.8455, -0.3497, 0.6673],
[-0.7936, -0.8073, -0.3339, 0.6372],
[-1.7046, -1.7340, -0.7172, 1.3686],
[-0.2724, -0.2771, -0.1146, 0.2187]])
If a rotation is applied to the system, this matrix will transform with the representation \(D_x \otimes D_y\) (the tensor product representation).
Which can be represented by
R = o3.rand_matrix()
D_x = irreps_x.D_from_matrix(R)
D_y = irreps_y.D_from_matrix(R)
plt.imshow(torch.kron(D_x, D_y), cmap='bwr', vmin=-1, vmax=1);
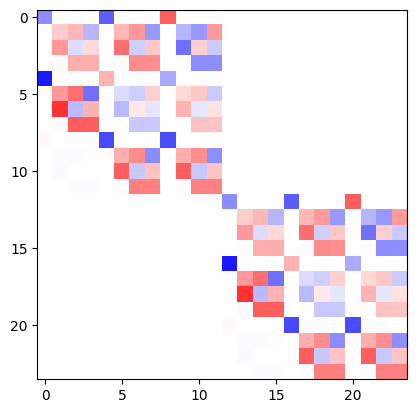
This representation is not irreducible (is reducible). It can be decomposed into irreps by a change of basis. The outerproduct followed by the change of basis is done by the class e3nn.o3.FullTensorProduct.
tp = o3.FullTensorProduct(irreps_x, irreps_y)
print(tp)
tp(x, y)
FullTensorProduct(2x1o x 1x0e+1x1e -> 2x0o+4x1o+2x2o | 8 paths | 0 weights)
tensor([-0.0606, -0.7539, -0.6943, -0.1569, -0.8311, -0.7936, -1.7046, -0.2724,
0.3364, -0.9920, -0.0937, 1.0488, -0.6465, 0.9900, -0.2037, -0.3194,
-0.0380, -0.1582, 0.9712, 0.2547, -1.4622, -0.3453, 0.8867, 0.7255])
As a sanity check, we can verify that the representation of the tensor prodcut is block diagonal and of the same dimension.
D = tp.irreps_out.D_from_matrix(R)
plt.imshow(D, cmap='bwr', vmin=-1, vmax=1);
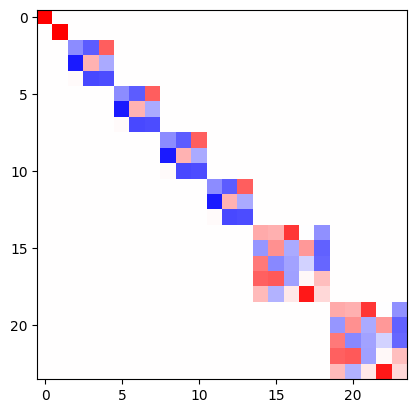
e3nn.o3.FullTensorProduct is a special case of e3nn.o3.TensorProduct, other ones like e3nn.o3.FullyConnectedTensorProduct can contained weights what can be learned, very useful to create neural networks.